操作系统
硬件
运算器、控制器、存储器、输入设备、输出设备 5 个部分也被称为冯诺依曼模型。
CPU
内部有寄存器、控制单元和逻辑运算单元等
总线
地址总线(用于指定 CPU 将要操作的内存地址)、数据总线(用于读写内存的数据)、控制总线(用于发送和接收信号,中断、设备复位等信号)。
一般流程为通过地址总线来指定内存的地址,控制总线控制是读或写命令,然后通过数据总线读取数据。
存储器
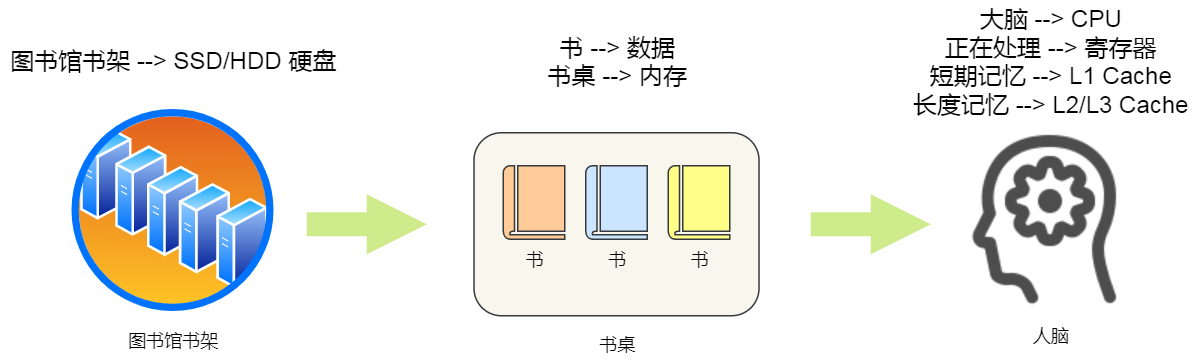
对于存储器,它的速度越快、能耗会越高、而且材料的成本也是越贵的,以至于速度快的存储器的容量都比较小。
- 寄存器;
- CPU Cache;
- L1-Cache;
- L2-Cache;
- L3-Cahce;
- 内存;
- SSD/HDD 硬盘
CPU缓存
CPU每次读取数据都是先读取缓存中的数据,未命中才会去内存中查询,然后在写到缓存当中,CPU再从缓存中读取
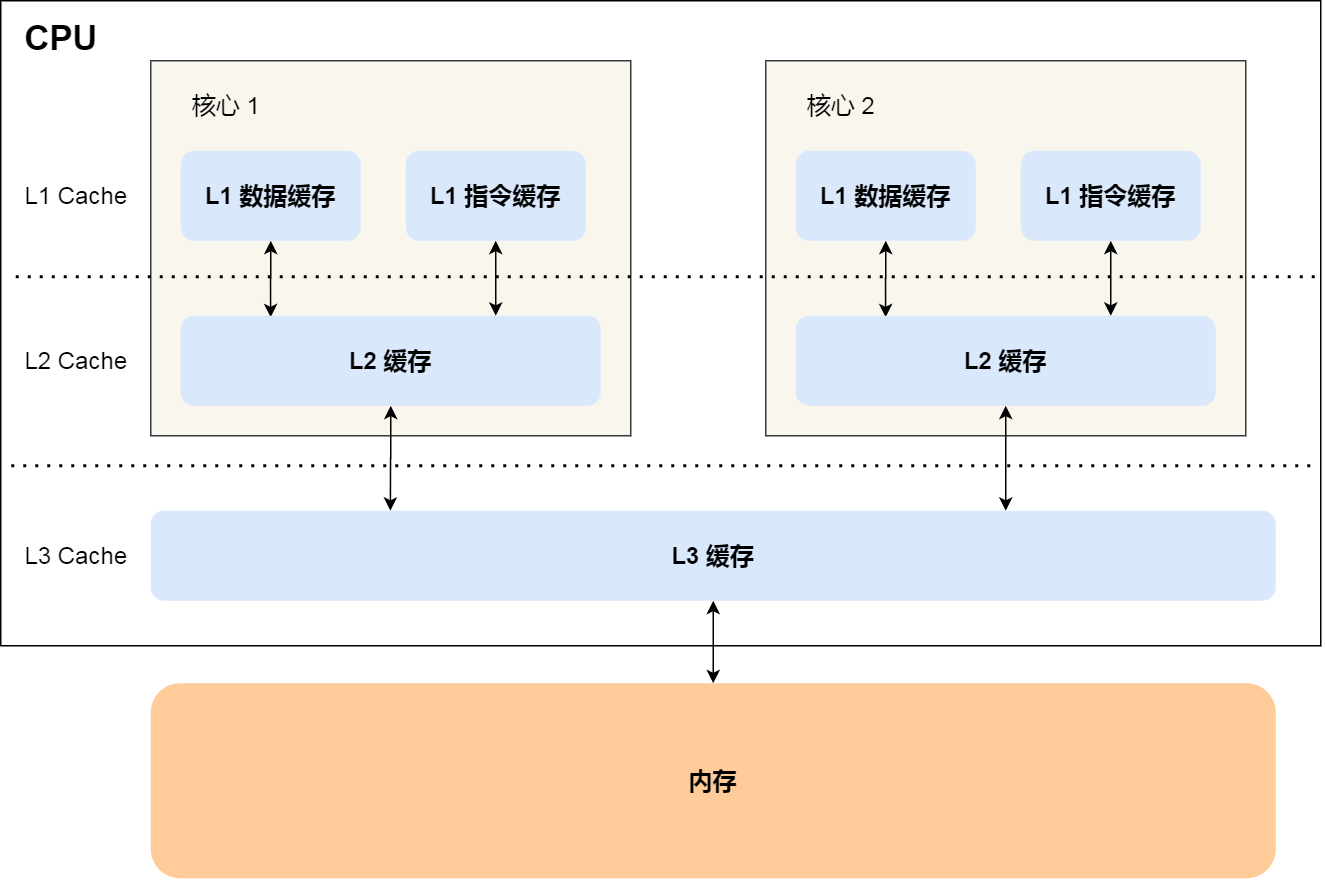
CPU Cache 的数据是从内存中读取过来的,是以Cache Line缓存行为单位
Cache Line
如果读取的数组不足64字节,那么就会顺序加载后面的数据,(如数组int【100】数组,一次就会读取16个int值,下标0-15(64/4))
内存映射
直接映射(取模加组标记),组相连,全相连
如何写出让 CPU 跑得更快的代码?
- 提高数据缓存的命中率,尽量读取一段顺序数据,能利用cpu的一次读取一个cacheLine的特性
- 提高指令缓存的命中率,尽量都执行同一分支的代码
- 提高多核心cpu缓存的命中率,L1,L2的是核心独有的,L3是共享的,当一个线程被不同核心执行的时候L1、L2命中率降低,可以把线程绑定到CPU核心上,linux可以通过sched_setaffinity方法
CPU缓存一致性
当数据写入cache之后,内存中的数据和cache数据会发生不一致
- 写直达(写回内存的时候,如果缓存中存在的话,先写缓存)
- 写回(在把数据写入到 Cache 的时候,只有在缓存不命中,同时数据对应的 Cache 中的 Cache Block 为脏标记的情况下,才会将Cache Block 中的数据写到内存中,而在缓存命中的情况下,则在写入后 Cache 后,只需把该数据对应的 Cache Block 标记为脏即可,而不用写到内存里。)
多核心缓存一致性
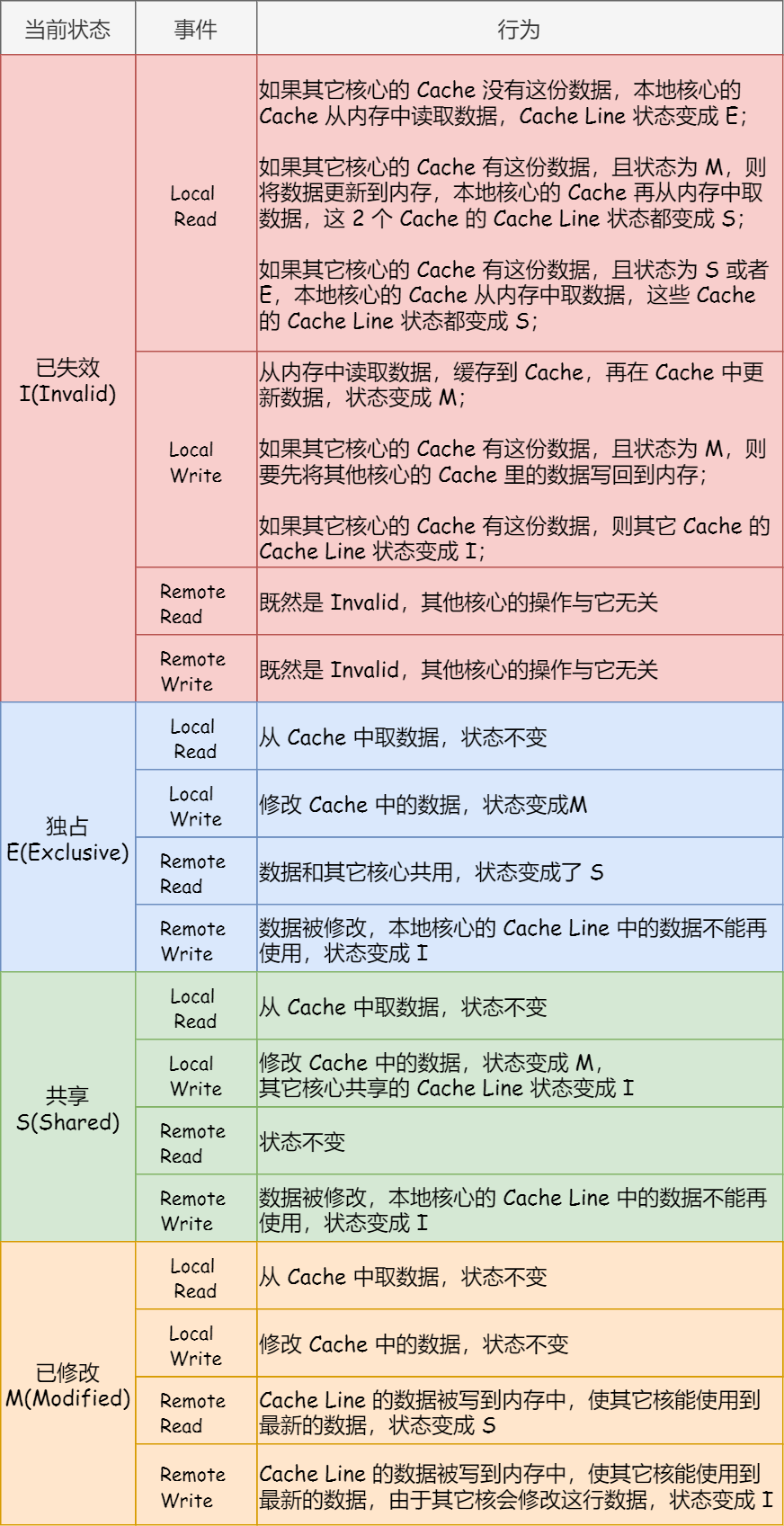
MESI
四种状态 Modified(已修改)Exclusive(独占)Share(共享)InValidated(已失效)
读数据
如果单个核心去读这个数据到Cacheline,其他核心没有该数据,则标记为独占,要是其他核心读取了数据,就标记为共享
写数据
如果该数据是已修改状态,不变
如果该数据是共享则需要先广播其他核心缓存使其缓存失效,然后在修改该状态是已修改
如果该数据已失效,需要让持有该数据先写到内存,然后读取到cache,修改标记为已修改
伪共享问题
因此,这种因为多个线程同时读写同一个 Cache Line 的不同变量时,而导致 CPU Cache 失效的现象称为伪共享(*False Sharing*)。
int A,B这样的话这两个变量是可能在同一个cache line当中的,因为cacheline 大小默认64 字节,这两个变量值占了8个字节,可能会发生伪共享
解决方法
- 在 Linux 内核中存在
__cacheline_aligned_in_smp宏定义,是用于解决伪共享的问题。 - Java 并发框架 Disruptor 使用「字节填充 + 继承」的方式,来避免伪共享,字节填充,RingBufferPad中使用前置填充7个final Long值,ring buffer中还使用了后置填充 7个final Long值,那么其他变量的读写就不会影响
虚拟内存
单片机的cpu是直接操作内存的物理地址(没有操作系统),并且在相同地址空间内存中不能同时运行两个程序的
虚拟内存的目的是为了将进程所用的地址隔离开来,操作系统会通过一种机制,将不同进程的虚拟内存地址映射到不同的物理内存地址。
操作方式
内存分段
虚拟地址-》(段选择因子)段号+偏移量
段号-》段表-》物理内存起始地址+段界限
偏移量-》物理内存起始地址+偏移量-》实际地址
缺点
内存碎片主要分为,内部内存碎片和外部内存碎片。
- 内存碎片(分段法,有多少内存分配多少内存,不会产生内部碎片,但是每个段长度不固定,不能恰好分配,就会产生外部碎片,可以通过内存交换的方式,先将该部分内存写到硬盘当中,然后再写回去)
- 内存交换效率低(如果占用内存很大,那么整块内存都需要发生交换)
内存分页
页是把整个虚拟和物理内存空间切成一段段固定尺寸的大小,MMU(内存管理单元)就是负责这块的,页表项为内存空间/页容量
- 虚拟地址-》页号+偏移量
- 页号-》页表-》物理基地址
- 偏移量-》物理基地址+偏移量-》实际地址
缺点
- 每页固定长度,虽然消除了外部碎片,但是每个页中不一定被填满数据
- 交换速率快了,当内存不够的时候将最近没被使用的页换到硬盘,等需要的时候再换出
- 要映射到所有的地址空间,每个进程一个页表,每个页表也会占用一定内存,会过于庞大
多级页表
在32位,内存4gb,页大小4kb的时候
通过将页表项拆分成两级,第一级页表最多4KB,而二级页表最多4MB,容量上反而多了4kb,但是但如果某个一级页表的页表项没有被用到,也就不需要创建这个页表项对应的二级页表了,即可以在需要时才创建二级页表。局部性原理不一定所有的一级页表项里都有内容
而64为就需要4级页表来进行处理,速度大大下降,后面引入了TLB(页表缓存)
段页式管理
段号、段内页号和页内位移

